
Nov 25, 2025
Summary
Millions of Images in 30 Days: A leading AI model builder sourced millions of de-identified imaging studies in a month of contract execution via the Protege data platform.
Single Licensing Source for Aggregated Data: Protege aggregated multiple imaging partners and worked with the AI company’s researchers to translate clinical requirements into deliverable datasets within the strict timeline and under a single data licensing agreement, unlocking scale for the data buyer.
New Commercial Opportunities for Multiple Data Partners: The scale and breadth of the leading AI model builder’s request required multiple data sources — for these providers, working with Protege unlocked exciting new revenue opportunities that leveraged their existing data assets while maintaining licensing protections.
Protege Research-Based Curation: The Protege Data Lab developed and applied custom data curation techniques to filter to studies with positive findings only.
Future Connected Requests: Protege continues to work with the AI builder to curate additional datasets for post-training, fine-tuning, and evaluation. Notably, ongoing data requests such as EHR data can be connected back to the initial imaging cohort to create new multimodal datasets.
Massive Training Data Volume, 1-Month Turnaround
A leading AI model company building for healthcare AI use cases came to Protege looking to accelerate their imaging model’s performance, focusing on a radiology use case. Specifically, the team required millions of high-quality, de-identified imaging studies with radiology reports that were representative of the broader population.
This is a common request to the Protege healthcare team. Protege works with dozens of data aggregators and healthcare providers to create one of the world’s leading healthcare datasets across different modalities and at scale.
However, scoping the data request with the AI company quickly revealed that there were additional hurdles beyond the raw data alone:
Speed: The AI researchers needed a 30-day turnaround, not the typical months that is commonly needed for healthcare data transfer.
Volume: Millions of studies and linked reports for the same modality that no single partner could cover alone.
Partner Breadth: Multiple data sources required to meet the requested volume, with each source presenting its own nuances and agreement structures.
Data Diversity: Studies distributed across different body parts to provide a representative sample.
Custom Data Curation: Researchers requested only studies with positive (abnormal) findings alone, rather than all studies and records available.
These additional factors were key for this particular AI data buyer, and Protege’s ability to deliver on each of these parameters ultimately led to a stepwise increase in the number of imaging studies and connected radiology reports the AI company had available to develop its next generation models.
“Speed and scale were non-negotiable,” explained Protege’s Head of Healthcare Sales Nick Zambruno. “Protege translated the buyer’s strict clinical criteria into a concrete, contractable data plan—and shipped on time.”
Overcoming Roadblocks to Unlock Foundational Data
Each of the hurdles noted by the leading AI company represent common concerns from AI companies searching for high-quality healthcare data specifically for training data use. Protege addresses each of the roadblocks head on to unlock important real world data sources for AI model training needs.
Speed
The healthcare data procurement process traditionally takes months, if not more than a year — this is especially true for massive data volumes at scale. However, Protege shortens this process dramatically through the Protege platform: dozens of vetted data partners with large datasets spanning different modalities, with all pre-scoped specifically for suitability for AI training and evaluation data use cases.
By working with Protege, partners are already prepared for the data preparation and delivery process needed to transfer large datasets while maintaining strict privacy standards and HIPAA compliance. This cuts out unnecessary back-and-forth wrangling with data partners.
Volume (and De-Identification)
Pulling, de-identifying, and quality-controlling millions of studies typically requires all-hands-on-deck from data providers, which is difficult to execute under tight timelines. This is especially true when multiple partners and modalities are involved in a single data delivery process.
Protege team members are experts in health data de-identification, allowing Protege to control what signal is lost versus maintained as a part of the de-identification process at scale. This still applies when multiple datasets and partners are involved, and the Protege data delivery process also supplies third party certification that confirms proper data de-identification protocols.
Partner Breadth
Typically, working with independent partners means that each and every partner requires separate agreements, and each data request requires a dedicated scope of work. This quickly becomes unwieldy when multiple partners are involved and need to be negotiated with — borderline impossible when the expected turnaround time is weeks, not months to a year.
However, in this case no single healthcare data source had the vast amount of data required for this AI pre-training data use case. This typically would prevent healthcare data providers from accessing these sort of AI training data deals that required partnering across different data sources to fulfill a single deal request.
To fill the gap, Protege functions as the connective tissue between these data partners and the end AI data buyer by securing individual agreements with a broad network of healthcare data providers. This enables the AI companies to work with a single point of contact that handles all the other data partners in tandem, rather than navigate a spiderweb of disparate partners in a short period of time.
Ultimately for the data providers, Protege unlocks new deal opportunities that stretch beyond the typical healthcare data requests that come from outside the AI world. Connecting the different data sources creates a win-win for individual data providers, who are then able to participate in large-scale AI training data requests while maintaining clear licensing protections that are standard for the industry.
Data Diversity
This radiology use case called for a diverse range of studies that were balanced across different parts of the human body. This made it critical that the data was correctly distributed across the body, despite the request including millions of patient studies.
The Protege Data Lab instituted strict data checks and quality controls to ensure that key thresholds for data diversity were being met as the data was being curated. This gave the company AI researchers the peace of mind that the end dataset they were purchasing met their training data criteria and could be effectively used for AI model development.
Custom Data Curation
Because the company’s AI researchers were looking to train their models to improve in clinical diagnostic situations that involved patients with acute findings, the data they wanted for training needed to reflect only certain scenarios, rather than any imaging study.
The Protege Data Lab research team applied its own methodology to isolate the dataset to only include imaging studies that matched the inclusion criteria that the AI research team required, while also continuing to enforce the body-region distribution thresholds that ensured data diversity.
Data Delivery
Once the data was curated and ready for delivery, the Protege team ensured that there was expert determination run on the final dataset — as is the case for all Protege-delivered healthcare data — to ensure privacy standards were upheld. This also ensured that patient de-identification was maintained as the data was transferred from the source to the end buyer.
For the data transfer process itself, Protege has built a delivery system that allows for the transfer of hundreds of terabytes and millions of files to be delivered in a matter of hours. Once the data sources and providers were ready, the Protege data team used this system to transfer the data across cloud providers to the end AI company buyer.
An Ongoing Partnership
While the AI company’s initial request focused around volume and speed of delivery, subsequent data projects have involved different modalities and use cases.
Many of these involve connecting additional modalities to this original imaging data request. For example, connecting claims data or other EHR data helps provide a fuller patient picture across time. This unlocks even deeper context for the healthcare AI models to use as training data, which then improves AI model performance in healthcare scenarios.
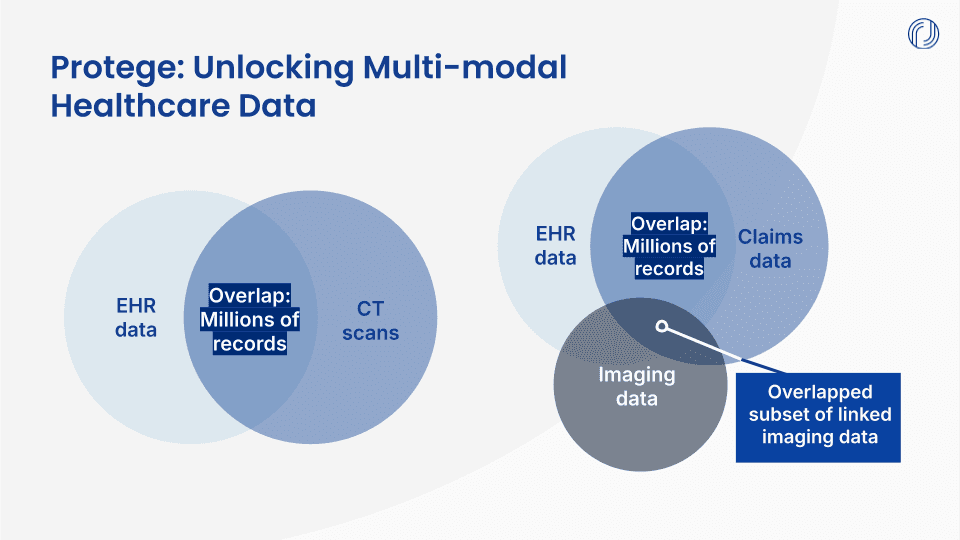
This is exactly where Protege’s combination of healthcare data aggregated across dozens of partners and the many healthcare modalities ranging from CT scans to MRIs to EHR to pathology slides and more come into play. This can be particularly important for fine-tuning healthcare AI models for specialized use cases, such as complex cancer diagnosis and clinical triage situations.
Interested in learning more about Protege’s healthcare datasets and AI data expertise? Contact us at contact@withprotege.ai.